Forest plot at a glance
Posted on 1st July 2016 by Tran Quang Hung

The evidence-based healthcare house begins with single-study bricks.
With time, the bricks accumulate. More and more research is conducted. Both observational and interventional.
If enough similar single studies in a given field are conducted, the past results can be combined. And boom. We get a new result – more reliable – with a combined population, bigger than any prior population. This is known as a meta-analysis.
In this kind of study, we often see a graph, called a forest plot, which can summarise almost all of the essential information of a meta-analysis.
Let’s find out how to read a forest plot.
Pros and cons of a forest plot
There are 3 main things we need to assess when reading a meta-analysis:
- Heterogeneity. The differences in the results, methodology or study populations used in the included studies.
- The pooled result. The overall combined result derived from combining (‘pooling’) the individual studies.
- Publication bias. Although the intent of a meta-analysis is to find and assess all the relevant studies meeting the inclusion criteria, this mission is not always possible. Some studies can be missed because they are not written in English, or because they show non-significant results (so they have a lower chance of being published).
A forest plot does a great job in illustrating the first two of these (heterogeneity and the pooled result). However, it cannot display potential publication bias to readers. A funnel plot can do that instead.
How to read a forest plot
Often, we have 6 columns in a forest plot.
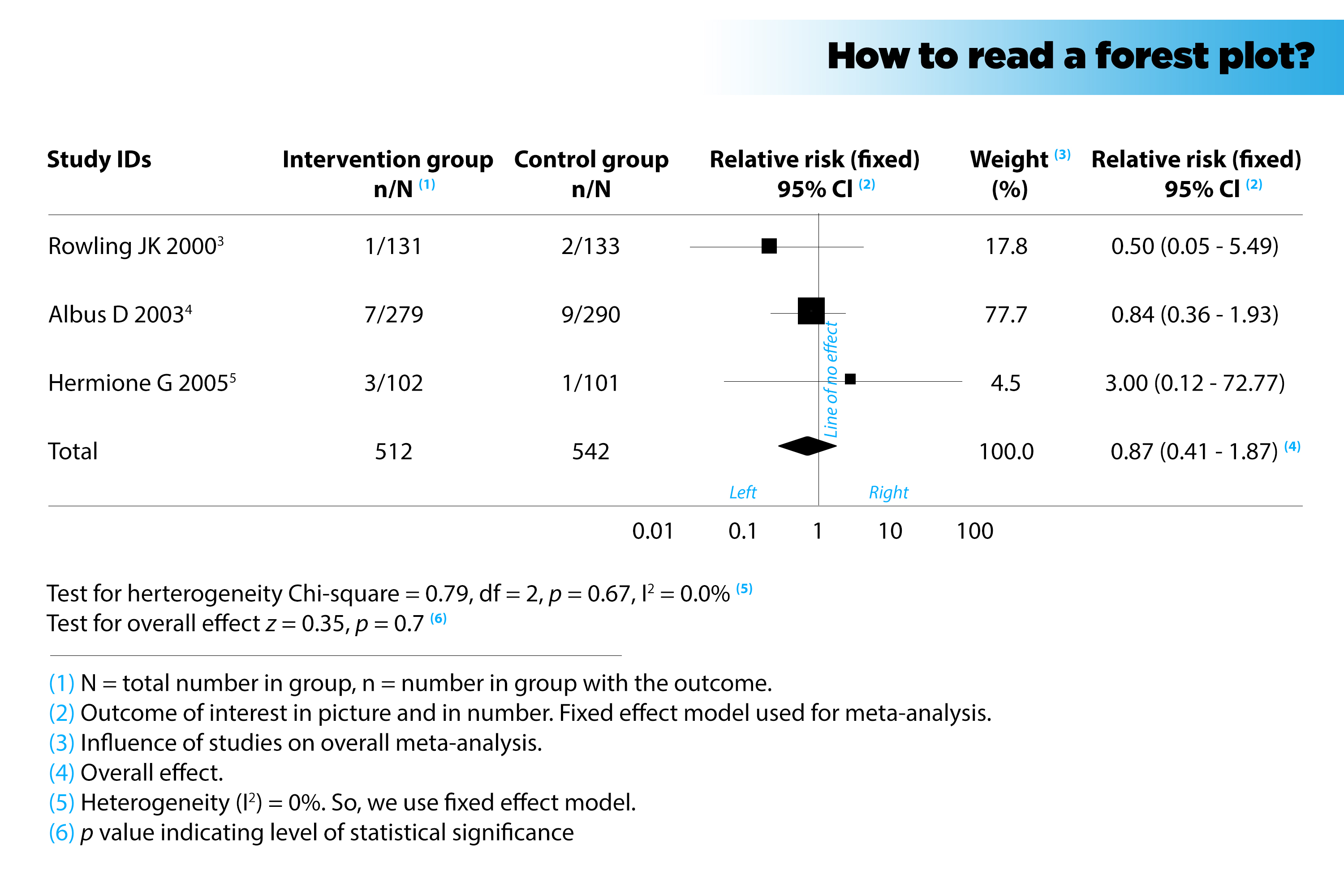
Column 1: Studies IDs
The leftmost column shows the identities (IDs) of the included studies. Studies are represented by the name of the first author and the year of publication, often arranged in time order.
Column 2 and column 3: Intervention group n/N and Control group n/N
Next, to the right, we meet some data from the intervention group and the control group from each study.
n indicates the number of patients having the outcome of interest, while N represents the total number of patients in that group.
For instance, in the study of Rowling et al (2000), 1 out of 131 participants in the intervention group has the outcome of interest, compared with 2 out of 133 participants in the control group.
Column 4: Relative risk (fixed) 95% CI
The next column visually displays the study results. The boxes show the effect estimates from the single studies, while the diamond shows the pooled result.
The horizontal lines through the boxes illustrate the length of the confidence interval. The longer the lines, the wider the confidential interval, the less reliable the study results. The width of the diamond serves the same purpose.
The vertical line is the line of no effect (i.e. the position at which there is no clear difference between the intervention group and the control group).
If the outcome of interest is adverse (e.g. mortality), the results to the left of the vertical line favour the intervention over the control. That is, if result estimates are located to the left, it means that the outcome of interest (e.g. mortality) occurred less frequently in the intervention group than in the control group (ratio < 1).
If the outcome of interest is desirable (e.g. remission), the results to the right of the vertical line favour the treatment over the control. That is, if result estimates are located to the right, it means that the outcome of interest (e.g. remission) occurred more frequently in the intervention group than in the control group (ratio > 1).
The last possibility: if the diamond touches the vertical line, the overall (combined) result is not statistically significant. It means that the overall outcome rate in the intervention group is much the same as in the control group. This is the case in the figure above.
Column 5: Weight (%)
For the next column over, the weight (in %) indicates the influence an individual study has had on the pooled result. In general, the bigger the sample size and the narrower the confidence interval (CI), the higher the percentage weight, the larger the box, and more the influence the study has on the pooled result.
Column 6: Relative risk (fixed) 95% CI
The rightmost column contains exactly the same information as is contained in the diagram in column 4, just in numerical format. So, we can observe the data both in picture and in number. This can be either the 95% CI of odds ratio (OR) or the 95% CI of relative risk (RR).*[See the bottom of this blog for a brief explanation of the difference]. The diagram above shows relative risk. When the 95% CI does not include 1, we can say the result is statistically significant.
More information is found at the lower left corner of the plot.
The p-value indicates the level of statistical significance. If the diamond shape does not touch the line of no effect, the difference found between the two groups was statistically significant. In that case, the p-value is usually < 0.05.
The I^2 indicates the level of heterogeneity. It can take values from 0% to 100%. For a quick and simple rule of thumb: if I^2 ≤ 50%, studies are considered homogeneous; if I^2 > 50%, studies are considered heterogeneous. Although some documents suggest that we can use the value of I^2 as foundation to determine whether we should use the fix-effect model or random-effect model, the choice shouldn’t be made solely on the basis of I^2. You can read more about this here: bit.ly/2atmmGU.
***
So, we’ve reached the end of the ‘how to read a forest plot’ tutorial.
Hope it helps.
Feel free to leave comments if you are still confused about forest plots.
***
[You can read more about the difference between odds and risk ratios here under the ‘odds ratios and relative risks’ section or here. But briefly, odds ratio is the number of participants in the group who achieve a stated end-point divided by the number of patients who do not. Risk ratio, as opposed to odds ratio, is the number of participants in the group who achieve the stated end-point divided by the total number of patients in the group].
All the images in this blog have been created by mitis
Read more of Tran’s blogs here…
Efficacy of drugs: 3 examples to get you to truly understand Number Needed to Treat (NNT)
How did they determine diagnostic thresholds: the stories of anemia and diabetes
Key to statistical result interpretation: P-value in plain English
Surrogate endpoints: pitfalls of easier questions
Why should medical students know about kappa value?


No Comments on Forest plot at a glance
Hi Dipak. Thank you for your question. If the diamond was narrower horizontally, then this would indicate a smaller 95% confidence interval. It may help you to take a look at this other blog we have on Forest Plots, as that has a smaller interval and will show you the figures accordingly: https://s4be.cochrane.org/blog/2016/07/11/tutorial-read-forest-plot/. I hope that helps.
5th May 2023 at 2:48 pmDear Sir
5th May 2023 at 4:39 amwhat will be ith interpretation if the Diamond is vertically wider than horizontal?
Very very useful. I have understood forest plots gragh better
11th September 2021 at 7:22 pmGreat explanations – thanks.
23rd March 2021 at 9:36 amheltrawy@yahoo.com
Hello,
Thanks this was really helpful!
Can I just ask: it says here l^2 = 0.0% but I thought the studies appeared to be heterogenous given RR at different sides of 1? Or am I confused?
Thanks! Alice
21st March 2021 at 11:11 amThis was great! Thank you
19th February 2019 at 1:28 amThank you. Awesome
27th October 2018 at 3:29 pmThis is a really great post -keep them coming!
26th October 2018 at 10:30 pmHow is the pooled result (summary) calculated?
14th May 2018 at 8:27 amIs it the average of all the independent results? How do we obtain the left, right and central values for the pooled result?
having my final tmw, that really helped
22nd April 2018 at 9:23 amthanks
Very easy to understand.Thanks a lot.
29th January 2018 at 6:12 amHi, I was wondering under the Forest plot can you explain the Z value?
26th January 2018 at 6:37 amGreat explanations – thanks.
(only one complaint- in the pretend names in the sample plot, Albus died in ’97 in the harry potter books…so he couldnt publish in 2003 haha) :)
10th July 2017 at 10:15 pmNice clear description – thanks
18th November 2016 at 3:16 amVery interesting post. The only aspect that seems strange is considering non-English written articles a source of publication bias. Oposetly, for me, limiting the language of a bibliographic search should be considered a publication bias.
3rd July 2016 at 2:56 amThanks for your comment, Abrahao. I guess you’re getting me wrong, cause all I mean is that “Some studies can be missed because they are not written in English” => the absence of those articles contributes to the publication bias.
4th July 2016 at 12:18 pm