Don’t confuse “no evidence of a difference” with “evidence of no difference”
Posted on 4th May 2018 by Bethan Copsey

This is the thirtieth blog in a series of 36 blogs based on a list of ‘Key Concepts’ developed by an Informed Health Choices project team. Each blog will explain one Key Concept that we need to understand to be able to assess treatment claims.
Evidence vs effectiveness
A systematic review of treatments usually aims to answer the question: what are the effects of treatment A compared to treatment B?
However, a review cannot always answer this question. The studies which make up the evidence base will provide information about the effects of the two treatments. However, if there is insufficient evidence, we cannot assess whether they differ.
When interpreting the results of systematic reviews (and other studies), it is important that we don’t confuse “no evidence of a difference” with “evidence of no difference”.
So what’s the problem?
The issue here is that when there is no statistically significant difference between treatment A and treatment B, people may wrongly assume that this necessarily means the two interventions are equivalent. Even if a statistically significant difference does not exist, it is still possible that there is a clinically relevant difference. It might be that one treatment is better than the other but the difference is not statistically significant because the number of outcomes is too small to detect it.
How can I avoid this?
The best way to avoid this problem is to check the confidence interval. If the 95% confidence interval includes both a clinically relevant effect and no effect, it suggests that we can’t tell whether the treatment is effective or not because there is not enough evidence.
When is there “No evidence of a difference”?
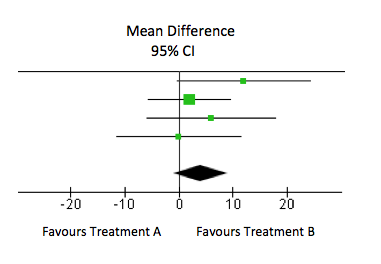
In this forest plot, the overall result (as shown by the diamond) is a mean difference of 4.02 (95% confidence interval: -1.06 to 9.11). This difference is not statistically significant (the confidence interval crosses 0). However, this does not mean that there is no effect. Let’s say a clinically important difference on this outcome measure is 8 points. The 95% confidence interval includes 8 so the results suggest that we cannot be certain that a clinically relevant difference does not exist. This is usually because there are too few treatment outcomes so the study is underpowered.
When is there “Evidence of no difference”?
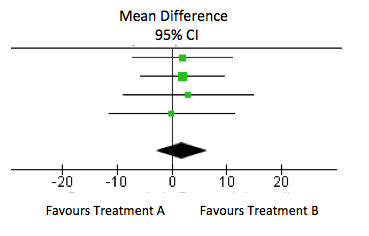
However, if the result is close to zero and the confidence interval is narrow, this suggests that there is no effect. In the forest plot below, the overall result is mean difference of 1.81 (95% confidence interval: -2.95 to 6.57). This does not include 8 points and so this suggests that there is no clinically meaningful difference.
In order to provide further evidence that two treatments are equally effective, we may decide to use non-inferiority or equivalence trials to assess whether useful treatment effects can be confidently excluded.
Why is there no evidence?
“No evidence” doesn’t always mean that there are no studies on the treatment. Sometimes it just means that there are too few data or not enough studies to justify any strong conclusions about treatment effects. Similarly, there may be quite a few studies but if they are all quite small, you may still not have enough outcomes to be able to assess whether effects exist. Also, if your study has a binary outcome (e.g. did the person fall or not), you may have little evidence because you don’t have enough events (e.g. if very few people fell).
Even if there are several included studies with larger sample sizes, there may be other reasons why a review concludes that there is insufficient evidence. A review may state that there is ‘inadequate evidence’ if there is low quality evidence because:
- the included studies were poor quality – if there were no high quality studies, we may not be convinced enough by their results
- there is indirectness – if a review on the effect of a drug on blood pressure only includes smokers, we may not feel that this is enough evidence to suggest whether it is effective in non-smokers
- there is high statistical heterogeneity – the results of the studies are not consistent (e.g. where there are large effects in some studies but smaller effects in others).
Key points to remember:
- If a result is not statistically significant, this does not always mean that the treatment is ineffective.
- Check the confidence interval to see if it includes a clinically important effect.
- Look at the quality of the evidence as well as the summary result.
- For more information, take a look at: Altman, D. G., & Bland, J. M. (1995). Statistics notes: Absence of evidence is not evidence of absence. Bmj, 311(7003), 485.


