A beginner’s guide to standard deviation and standard error
Posted on 26th September 2018 by Eveliina Ilola
What is standard deviation?
Standard deviation tells you how spread out the data is. It is a measure of how far each observed value is from the mean. In any distribution, about 95% of values will be within 2 standard deviations of the mean.

How to calculate standard deviation
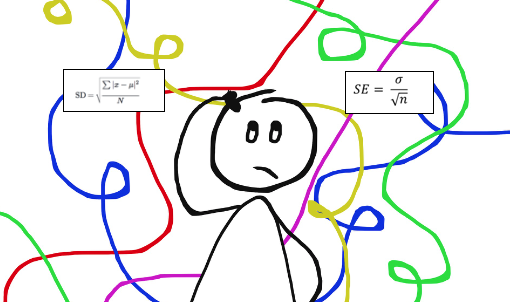
Standard deviation is rarely calculated by hand. It can, however, be done using the formula below, where x represents a value in a data set, μ represents the mean of the data set and N represents the number of values in the data set.
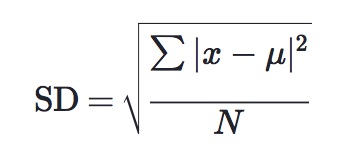
The steps in calculating the standard deviation are as follows:
- For each value, find its distance to the mean
- For each value, find the square of this distance
- Find the sum of these squared values
- Divide the sum by the number of values in the data set
- Find the square root of this
What is standard error?
When you are conducting research, you often only collect data of a small sample of the whole population. Because of this, you are likely to end up with slightly different sets of values with slightly different means each time.
If you take enough samples from a population, the means will be arranged into a distribution around the true population mean. The standard deviation of this distribution, i.e. the standard deviation of sample means, is called the standard error.
The standard error tells you how accurate the mean of any given sample from that population is likely to be compared to the true population mean. When the standard error increases, i.e. the means are more spread out, it becomes more likely that any given mean is an inaccurate representation of the true population mean.
How to calculate standard error
Standard error can be calculated using the formula below, where σ represents standard deviation and n represents sample size.
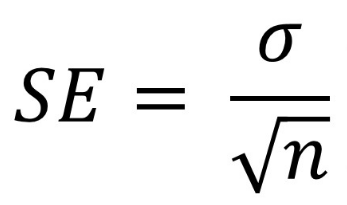
Standard error increases when standard deviation, i.e. the variance of the population, increases. Standard error decreases when sample size increases – as the sample size gets closer to the true size of the population, the sample means cluster more and more around the true population mean.
Images:
Image 1: Dan Kernler via Wikipedia Commons: https://commons.wikimedia.org/wiki/File:Empirical_Rule.PNGÂ
Image 3: https://toptipbio.com/standard-error-formula/
Sources:
http://www.statisticshowto.com/probability-and-statistics/standard-deviation/
http://www.statisticshowto.com/what-is-the-standard-error-of-a-sample/
https://www.statsdirect.co.uk/help/basic_descriptive_statistics/standard_deviation.htm

No Comments on A beginner’s guide to standard deviation and standard error
good
13th April 2023 at 1:02 pmIf it is allowable , I need this topic in the form of pdf
11th February 2023 at 12:21 pmThanks for the question Freddie. I have put it onto our Twitter account to see if any of the community can help with this. This article is interesting, but doesn’t answer your question of what to do when the error bar is not labelled: https://www.statisticshowto.com/error-bar-definition/. I wonder how common this is? I’ll post any answers I get via twitter on here.
10th February 2023 at 9:43 amHi
9th February 2023 at 9:41 pmI sometimes see bar charts with error bars, but it is not always stated if such bars are standard deviation or standard error bars. Is there some way to tell if the bars are SD or SE bars if they are not labelled ?