What are sampling methods and how do you choose the best one?
Posted on 18th November 2020 by Mohamed Khalifa

This tutorial will introduce sampling methods and potential sampling errors to avoid when conducting medical research.
Contents
- Introduction to sampling methods
- Examples of different sampling methods
- Choosing the best sampling method
Introduction to sampling methods
It is important to understand why we sample the population; for example, studies are built to investigate the relationships between risk factors and disease. In other words, we want to find out if this is a true association, while still aiming for the minimum risk for errors such as: chance, bias or confounding.
However, it would not be feasible to experiment on the whole population, we would need to take a good sample and aim to reduce the risk of having errors by proper sampling technique.
What is a sampling frame?
A sampling frame is a record of the target population containing all participants of interest. In other words, it is a list from which we can extract a sample.
What makes a good sample?
A good sample should be a representative subset of the population we are interested in studying, therefore, with each participant having equal chance of being randomly selected into the study.
Examples of different sampling methods
We could choose a sampling method based on whether we want to account for sampling bias; a random sampling method is often preferred over a non-random method for this reason. Random sampling examples include: simple, systematic, stratified, and cluster sampling. Non-random sampling methods are liable to bias, and common examples include: convenience, purposive, snowballing, and quota sampling. For the purposes of this blog we will be focusing on random sampling methods.
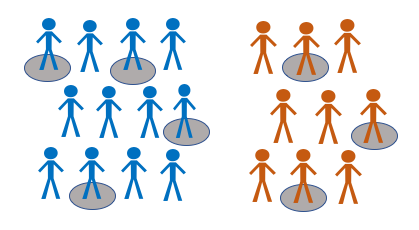
Simple
Example: We want to conduct an experimental trial in a small population such as: employees in a company, or students in a college. We include everyone in a list and use a random number generator to select the participants
Advantages: Generalisable results possible, random sampling, the sampling frame is the whole population, every participant has an equal probability of being selected
Disadvantages: Less precise than stratified method, less representative than the systematic method
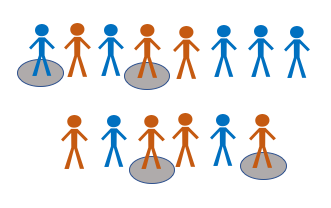
Systematic
Example: Every nth patient entering the out-patient clinic is selected and included in our sample
Advantages: More feasible than simple or stratified methods, sampling frame is not always required
Disadvantages: Generalisability may decrease if baseline characteristics repeat across every nth participant
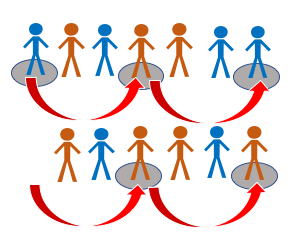
Stratified
Example: We have a big population (a city) and we want to ensure representativeness of all groups with a pre-determined characteristic such as: age groups, ethnic origin, and gender
Advantages: Inclusive of strata (subgroups), reliable and generalisable results
Disadvantages: Does not work well with multiple variables
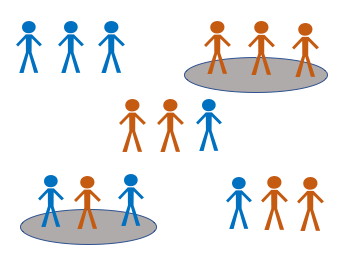
Cluster
Example: 10 schools have the same number of students across the county. We can randomly select 3 out of 10 schools as our clusters
Advantages: Readily doable with most budgets, does not require a sampling frame
Disadvantages: Results may not be reliable nor generalisable
How can you identify sampling errors?
Non-random selection increases the probability of sampling (selection) bias if the sample does not represent the population we want to study. We could avoid this by random sampling and ensuring representativeness of our sample with regards to sample size.
An inadequate sample size decreases the confidence in our results as we may think there is no significant difference when actually there is. This type two error results from having a small sample size, or from participants dropping out of the sample.
In medical research of disease, if we select people with certain diseases while strictly excluding participants with other co-morbidities, we run the risk of diagnostic purity bias where important sub-groups of the population are not represented.
Furthermore, measurement bias may occur during re-collection of risk factors by participants (recall bias) or assessment of outcome where people who live longer are associated with treatment success, when in fact people who died were not included in the sample or data analysis (survivors bias).
Choosing the best sampling method
By following the steps below we could choose the best sampling method for our study in an orderly fashion.
Research objectiveness
Firstly, a refined research question and goal would help us define our population of interest. If our calculated sample size is small then it would be easier to get a random sample. If, however, the sample size is large, then we should check if our budget and resources can handle a random sampling method.
Sampling frame availability
Secondly, we need to check for availability of a sampling frame (Simple), if not, could we make a list of our own (Stratified). If neither option is possible, we could still use other random sampling methods, for instance, systematic or cluster sampling.
Study design
Moreover, we could consider the prevalence of the topic (exposure or outcome) in the population, and what would be the suitable study design. In addition, checking if our target population is widely varied in its baseline characteristics. For example, a population with large ethnic subgroups could best be studied using a stratified sampling method.
Random sampling
Finally, the best sampling method is always the one that could best answer our research question while also allowing for others to make use of our results (generalisability of results). When we cannot afford a random sampling method, we can always choose from the non-random sampling methods.
Conclusion
To sum up, we now understand that choosing between random or non-random sampling methods is multifactorial. We might often be tempted to choose a convenience sample from the start, but that would not only decrease precision of our results, and would make us miss out on producing research that is more robust and reliable.


No Comments on What are sampling methods and how do you choose the best one?
Thank you for this overview. A concise approach for research.
21st September 2023 at 9:40 pmreally helps! am an ecology student preparing to write my lab report for sampling.
21st April 2023 at 9:01 amI learned a lot to the given presentation..
29th May 2022 at 1:54 pmIt’s very comprehensive…
Thanks for sharing…
Very informative and useful for my study. Thank you
12th June 2021 at 5:03 amOversimplified info on sampling methods. Probabilistic of the sampling and sampling of samples by chance does rest solely on the random methods. Factors such as the random visits or presentation of the potential participants at clinics or sites could be sufficiently random in nature and should be used for the sake of efficiency and feasibility. Nevertheless, this approach has to be taken only after careful thoughts. Representativeness of the study samples have to be checked at the end or during reporting by comparing it to the published larger studies or register of some kind in/from the local population.
28th May 2021 at 12:28 amThank you so much Mr.mohamed very useful and informative article
4th January 2021 at 6:21 am