Tutorials and Fundamentals

Descriptive vs inferential statistics: an overview
Statistics can help you understand a dataset. But first up, you need to know the difference between descriptive and inferential methods.
Statistics can help you understand a dataset. But first up, you need to know the difference between descriptive and inferential methods.

In this blog you will be able to understand the basic concepts about composite endpoints, their limitations and benefits, as well as an approach to how to interpret them.

This blog introduces you to funnel plots, guiding you through how to read them and what may cause them to look asymmetrical.

This blog is a review of a newly published book, which has the overall aim of giving health professionals a ‘working understanding’ of medical statistics.
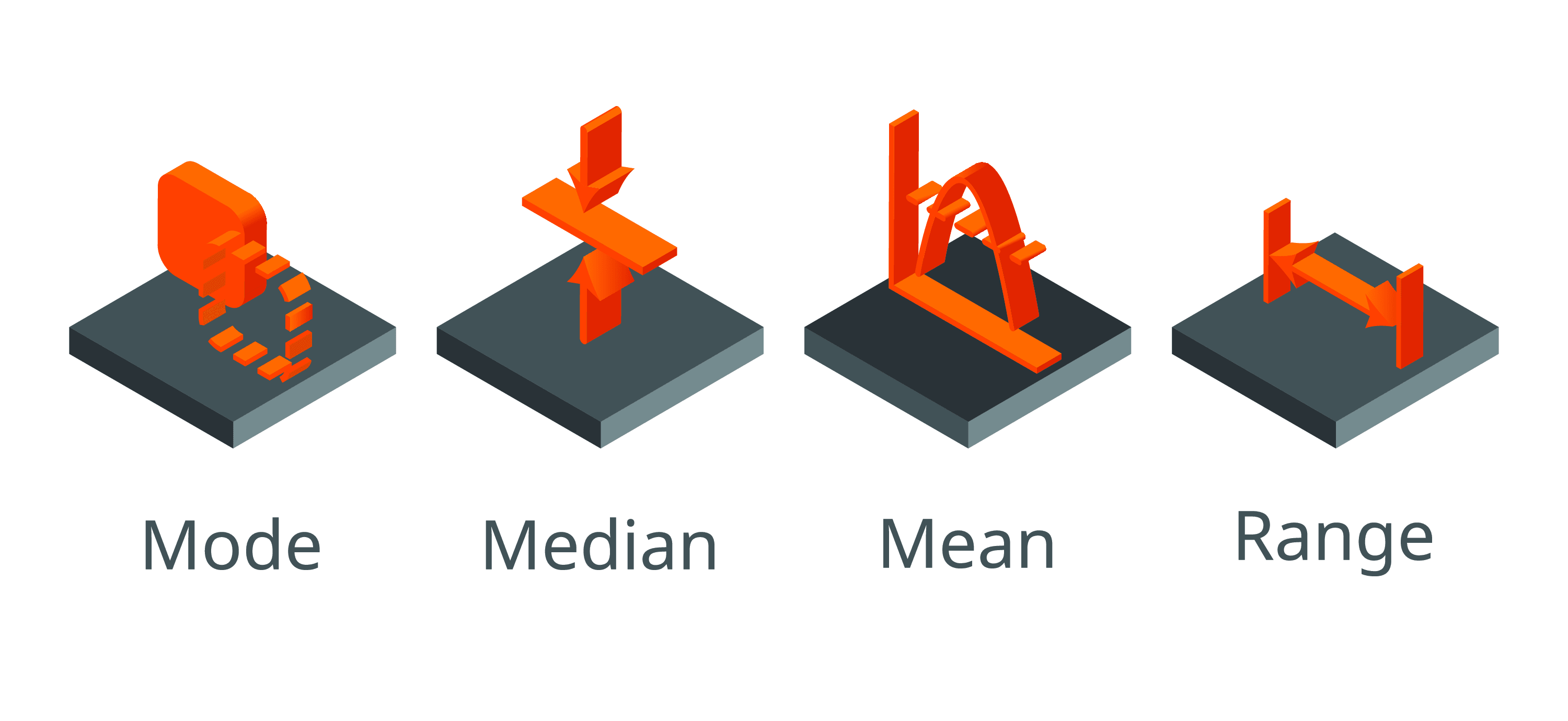
This tutorial provides an introduction to statistical averages (mean, median and mode) for beginners to the topic.
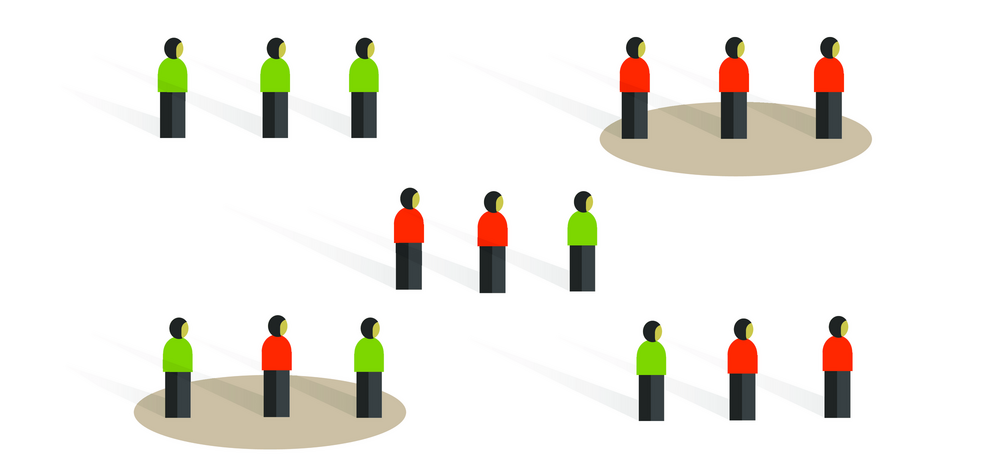
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.

Measures of variability are statistical tools that help us assess data variability by informing us about the quality of a dataset mean. This second of two blogs on the topic will look at coefficient of variation and the z-score.
Measures of variability are statistical tools that help us assess data variability by informing us about the quality of a dataset mean. This first of two blogs on the topic will cover basic concepts of range, standard deviation, and variance.

A tutorial for understanding and calculating probability. We go back to basics for beginners or for those just wanting a refresher.

This is the third in a three-part blog which will look at a few aspects of the topic in more detail like the cost-effectiveness plane, discount rates, and other key elements in health economic evaluation.

In the second of a series of blogs about economic analysis, Ana María explains the common techniques used in economic evaluation.

Learn more about the measures of central tendency (mean, mode, median) and how these need to be critically appraised when reading a paper.
In the first of a series of blogs about economic analysis, Ana María introduces us to the topic and why it is needed.
In this blog, Vighnesh provides an outline of multivariate analysis for beginners to this topic.

What is data dredging, how does it affect the p-value and what is its impact on the world around us?

A brief guide to prevalence and incidence with definitions, explanations and example calculations.
This blog introduces you to standardised mortality ratios. What are they, why are they used, how do you calculate them and what are their advantages and limitations.

Explaining basic knowledge of statistics with fun visualization tools and interactive functions.
The blog explains what we mean by – and how to calculate – ‘sensitivity’, ‘specificity’, ‘positive predictive value’ and ‘negative predictive value’ in the context of diagnosing disease.
What is ‘Responder analysis’ and what are the benefits and limitations of this approach? Read more in this blog from Giorgio Karam.

Randomized controlled trials (RCTs) can be subject to different kinds of bias. Read about different sources of bias in this blog and how much the magnitude of effect can be changed by the presence of bias.
This blog examines what heterogeneity is, why it matters, how you can identify and measure it and how you can then deal with it.

This blog introduces you to the concept of confounding. There is a clear explanation and then examples and methods to minimise the effect of confounding during study design and statistical analysis.
A beginner’s guide to standard deviation and standard error: what are they, how are they different and how do you calculate them?

Carryover effects can affect outcomes and results of research, and are important to consider, particularly in the design phase of a study.

A Finnish translation (thank you to Eveliina Ilola) of the nuts and bolts 20 minute tutorial from Tim Hicks: A beginner’s guide to interpreting odds ratios, confidence intervals and p-values.

Tarang Sharma was lead-author of a recent article entitled “The Yusuf-Peto method was not a robust method for meta-analyses of rare events data from antidepressant trials”. In this blog, Tarang gives more details about meta-analysis methods of rare events and sparse data, and why these can lead to misleading results.

This blog follows on from Ammar’s previous post on meta-analysis, and provides further details on the history, value and implementation of this approach.
This blogs provides an overview of linear regression. It is suitable for those with little to no experience of this type of analysis. This is not a guide on how to conduct your own analysis, but instead will serve as a taster to some of the key terms and principles of regression.

This blog explains what is meant by Type I and Type II errors in statistics. Whereby we can end up with false positive and false negative results.

This blog discusses the issue of statistical significance (whether a difference, such as an improvement in symptoms, is unlikely to have occurred by chance) vs. clinical significance (whether a difference, such as an improvement in symptoms, is meaningful and patient to patients).

This blog is a Portuguese translation of the blog ‘Meta-analysis: what, why and how’. Thanks to Cochrane Brazil for the translation.

This blog takes a detailed look at the issue of attrition bias (bias that can arise when participants drop out of a study). It also describes measures that can be taken by researchers to minimize this bias (including different types of statistical analyses).

Beware dodgy research (particularly when it’s pharmaceutical-funded)! This blog shines a spotlight on some of the appalling ‘tricks’ that researchers and sponsors can (and do!) play to help them get the results they want from their trials. From fiddling with the study design, to fiddling with the data analysis and ‘spinning’ results…
This blog provides a basic overview of: 1) what a meta-analysis is; 2) why they’re considered the ‘gold standard’ of evidence; and 3) how a meta-analysis is carried out.
This is a nuts and bolts tutorial published in Portuguese.

A nuts and bolts tutorial on how to read a forest plot, featuring a couple of exercises so that you can test your own understanding.

Let’s figure out how to get the essential information from a meta-analysis at a glance, by studying a forest plot.

Median has come to be known for its fair reflection in the case of outliers. However, it is not a perfect statistic. Let me tell you about 3 defects the median as a measure of average.

Let’s find out why physicians sometimes contradict each other from a statistical perspective. And see how students can learn from that.

Let’s figure out how the epidemiologists determine the diagnostic thresholds by studying the cases of anemia and type II diabetes.

Come with me. I’ll show you the best way to display the efficacy of a drug. And the pitfalls around it. Ladies and gentlemen, welcome to the world of Number needed to treat.

Confused about Hazard Ratios and their confidence intervals? This blog provides a handy tutorial.

This post talks about the real meaning of p-value. No fancy words. No complicated definitions. Only simple notions included.

“This treatment lowers your high risk of heart attack considerably”. Wait, what is “risk”? This post explains you a definition of risk that is useful to understand in health-related questions.

How can you tell if a variable is nominal, ordinal, or numerical? Why does it even matter? Determining the appropriate variable type used in a study is essential to determining the correct statistical method to use when obtaining your results. It is important not to take the variables out of context because more often than not, the same variable that can be ordinal can also be numerical, depending on how the data was recorded and analyzed. This post will give you a specific example that may help you better grasp this concept.

Know Your Chances: Understanding Health Statistics is one of the few easily digestible statistics books that teaches anyone the most basic principles and concepts how to question and see the reality behind health news, hype, claims and ads.

A description of the two types of data analysis – “As Treated” and “Intention to Treat” – using a hypothetical trial as an example

Deevia takes a look at ‘effect modification’ and ‘confounding’ and explains the differences.

This blog describes what is meant by a positive predictive value and a negative predictive value, their purpose and how they can be interpreted

Sense About Science explains how scientists cope with uncertainty and unknowns in research, whether or not that matters, and how we can practically use scientific results in spite of not always knowing everything.

YouTube video series by Dr. Aaron Carroll called Healthcare Triage, where his motto is, “To the Research!”

As calculating the mean is so popular it might lead to many intuitive misconceptions. Here are some precautions you can take when interpreting the mean.

Surrogate endpoints are like a double edged sword. Even though they do have some benefits on some occasions, they can easily mislead doctors into withdrawing the wrong conclusions. It is, therefore, important to use them with caution.

In search of a book with simple, comprehensible definitions and examples of clinical evidence? Do you want to take the first step in understanding common terms in clinical evidence as well as commonly used methods and their pitfalls? This review will inform you if this is the book you’re looking for.

Is this your first contact with evidence-based healthcare? This course is a perfect start…

What happens when you have a test result? Do you believe it, can you act on it? It all depends where you are. Check out this discussion of post-test probabilities and how they help in the interpretation of test results.

Sean reviews the Statistics Learning Centre’s Videos – a Youtube channel featuring a series of free tutorials which aim to help you learn the concepts of statistics from identifying types of data to performing t-tests in Excel.

On the uniform of every fine detective, badges which salute their sensitivity and specificity are worn. From crime to clinic, find out what defines these “pre-test” probabilities.

Pre-test probabilities can help clinicians select and interpret diagnostic tests. To see a recent, real life application check out Aaron’s review of “Diagnostic Accuracy of Point-of-Care Tests for Detecting Albuminuria” from the Annals of Internal Medicine.

I have a test, and I know its measure of sensitivity. What does this tell me? When should I use this test? How do I expect this test to perform? Read more about the clinical application of sensitivity.

On the uniform of every fine detective, badges which salute their “sensitivity” and “specificity” are worn. From crime to clinic, find out what defines these “pre-test” probabilities.

An introduction to the role of statistical power in the search for evidence.

GATE (Graphic Approach To Evidence Based Medicine) is a simplified diagram that is used to explain any quantitative study; from an RCT to a cohort.

Evidence-based medicine has a large variety of different sub-fields. Let’s begin our journey towards one of them – evidence-based physical examination.
The nuts and bolts 20 minute tutorial from Tim.

Revealing the truth behind rates, ratios and risk with QMP statistics tutorials. This is one of a series that helps with understanding of statistics and study design.

Understanding uncertainty is a site from the Winton programme based at the University of Cambridge, UK, that encourage healthy criticism of the statistics the media gives us.
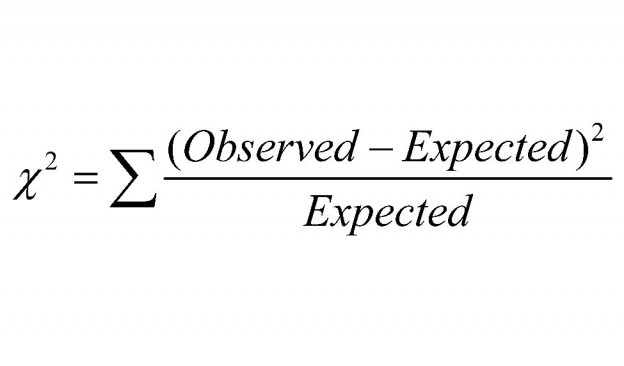
QMP Statistics tutorials talks you through chi-squared and t-tests – a useful resource for different statistical levels.

This tutorial teaches the essentials about the statistics in medicine and covers various aspects of normal distribution (ND): central limit theorem, properties of ND, NDs with different means and with different variances, variables that follow a ND, normal plot and introduction to t-distribution

QMP Medical Statistics Tutorials are a great place to start learning about the principles of evidence-based medicine. The probability & significance test, in my opinion, should be one of the first tutorials for a medical student.

A meta-epidemiological study published in the BMJ last month has found that smaller trials consistently report larger effect sizes.
A short article on the uses of Facebook friend finder…

Beginners often get confused with odds ratio and relative risk, which are almost used in same sense.
A simple way to understand both.

The QMP Medical Statistics tutorial that is designed to show you how to apply evidence-based medicine to clinical practice in a practical and logical manner.

This tutorial covers how to use appropriate statistical tests and what are confidence intervals and how do you use them.

This is a tutorial that looks at the statistical basis of randomised controlled trials, the theory behind meta-analyses and how to read a meta-analysis

This is a short, clearly written tutorial explaining the basic concepts of evidence-based medicine.

A short poem about regression to the mean illustrated with a few examples!
Evidence-Based Medicine is a growing field that has already made a tremendous impact on world healthcare. It’s only rational to teach it to medical students from the beginning, however, this is not always the case. Let me give you an example: me.
SPSS is a computer program used for statistical analysis. This tutorial will take you through a series of activities to help improve your SPSS skills.
In this medical statistics tutorial we will be looking at how the data that are collected by studies are summarized and presented in order to extract useful information. We will then start to look at how to analyse the data.

This pack is for 12-14 year olds learn how mathematicians use mathematical models to make predictions about epidemics.

CASP have created a from to help make sense of the information given in Cohort Studies.

12 questions to help you make sense of economic evaluations.
Register to become an S4BE Contributor